윈도우의 메모리를 알아 보기 전 Intel 80x86 계열에서의 메모리 처리 기법에 대해 먼저 알아보기로 하자.
1. 가상 주소
운영 체제에서 제공하는 메모리 관리기법으로 실제 메모리와 운영체제의 도움으로 하드디스크까지 메모리의 보조적인 기억장치(Paging Space)를 포함하는 주소를 의미한다.
 [그림1] 메모리의 가상 주소 및 실제 주소(출처 : 위키백과)
[그림1] 메모리의 가상 주소 및 실제 주소(출처 : 위키백과)
그림 2에서 메모리는 실제 물리적 메모리이며 페이지 파일은 pagefiles.sys에 할당된 디스크의 메모리 용량을 의미한다.
프로그래머의 입장에서는 가상 메모리의 주소를 사용함으로써 실제 메모리와 페이지 파일에 어떤 페이지를 올려놓을지에 대해서 고려하지 않고 주소로만 처리함으로써 복잡한 알고리즘에서 벗어날 수 있으며 해당 페이지를 실제 메모리에 올리는 메커니즘은 운영체제에서 수행함으로써 물리 메모리 충동과 같은 이슈사항을 최소한으로 줄일 수 있는 것이다.
이런 가상 주소를 사용하기 위한 방법으로 페이징과 세그먼트라는 개념이 존재한다.
해당 방법에 대해 알아보도록 하겠다.
2. 페이징 기법
페이징 기법을 설명하기 전에 페이지가 무엇인지 먼저 알아야할것이다.
우리가 실제 메모리를 사용하는 경우 일정 용량을 메모리로 사용하게 된다.
예를 들어 실제 메모리가 512KB의 시스템에서 1MB의 메모리를 필요로 하는 프로그램을 사용한다고 가정하자.
이런 경우 0~511KB의 부분만 메모리에 올려놓고 나머지 부분은 디스크에 놓은 후 512KB 이후의 메모리를 액세스 할때는 512KB이후의 메모리를 메모리에 올려야 할것이다.
간단한 상황이지만 어느쪽의 메모리가 필요한 것인가 또는 어느쪽의 메모리가 반복적으로 사용되는 경우를 생각하면 디스크와 메모리 간에 데이터 교환이 빈번히 일어날 것이며 이것은 서버에 큰 부하를 줄 것이라는 것을 쉽게 생각할 수 있다.
항상 요청하는 메모리는 예측할 수 없으므로 요구 메모리를 페이지(Page)라는 단위로 나누어 요청한 데이터 내용에 대해 Page 단위로 메모리에 적재하여 불연속적인 메모리 요청에 대해 처리할 수 있도록 하는 것이 페이징 기법이다.
이런 페이징 기법에서 가장 중요한 것은 하나의 페이지의 크기이다.
페이지의 크기가 너무 큰 경우 디스크와 메모리간의 스위칭(페이지 교체 기법)이 잦을 것이며 페이지의 크기가 너무 작은 경우에는 단편화가 일어날 수 있다. 여기서 페이지 교체 기법 과 단편화에 대해서는 뒤에서 알아보도록 하겠다.
그럼 실제 메모리와 가상 메모리의 블록에 대해 알아보도록 하겠다.
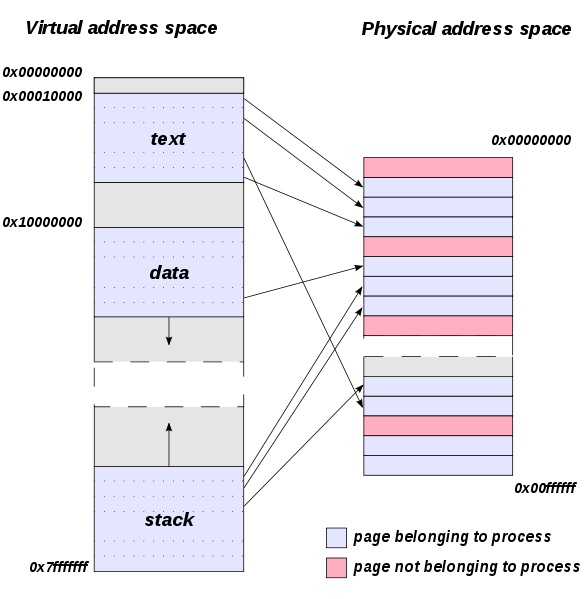
Frame(프레임) : 실제 Physical Memory를 일정한 크기로 나눈 블록
Page(페이지) : 가상 Memory를 일정한 크기로 나눈 블록

하나의 페이지가 프레임을 할당받으면 물리적 메모리에 페이지가 적재되며 그외의 페이지는 디스크에 저장되어지게 된다.
이런 페이지와 프레임간의 연관관계를 가지고 있는 테이블이 존재하는데 이것을 가르켜 페이지 테이블이라고 한다.
하나의 프로세스는 하나의 페이지 테이블(Page Table)을 가지고 있다.

[그림 4] Page Table, TLB(출처 : 위키백과)
 [그림 6] 디스크 조각모음
[그림 6] 디스크 조각모음
1. 가상 주소
운영 체제에서 제공하는 메모리 관리기법으로 실제 메모리와 운영체제의 도움으로 하드디스크까지 메모리의 보조적인 기억장치(Paging Space)를 포함하는 주소를 의미한다.
그림 1에서 보는 바와 같이 가상 메모리 주소는 실제 메모리 주소와 메핑되어 있으며 page 단위로 나누어져 있다.
page는 다음에 알아보기로 하며 해당 page는 process가 사용하고 있는 page와 process가 사용하고 있지 않는 page로 나뉘어져 있다.
process에 속해 있다는 의미는 해당 page가 process가 구동되는 과정에 사용되어지는 메모리라는 것을 의미한다.
여기서 그림 1을 보면 가상 메모리 주소의 크기가 물리 메모리 주소보다 큰 것을 볼 수 있다.
그 이유는 가상 메모리는 물리 메모리 주소 + 디스크의 일정량이기 때문이다.
C드라이브를 보면 pagefile.sys 라는 파일을 본 적이 있을 것이다.(물론 해당 파일은 설정에 따라 위치가 틀리다.) 해당 파일은 디스크 영역을 메모리와 같이 사용하기 위해 윈도우에서 생성한 파일이며 가상 메모리의 크기는 실제 메모리 + 해당 파일의 크기임을 알 수 있다.
(권장 값은 실제 메모리 * 1.5)
물리적 메모리와 가상 메모리의 값은 dxdiag에서 확인할 수 있으며 설정에 들어가서 확인할 수 있다.
http://www.youtube.com/watch?v=L2igH6O0ARM
(위 사이트는 메모리 설정 관련 사이트 임)

page는 다음에 알아보기로 하며 해당 page는 process가 사용하고 있는 page와 process가 사용하고 있지 않는 page로 나뉘어져 있다.
process에 속해 있다는 의미는 해당 page가 process가 구동되는 과정에 사용되어지는 메모리라는 것을 의미한다.
여기서 그림 1을 보면 가상 메모리 주소의 크기가 물리 메모리 주소보다 큰 것을 볼 수 있다.
그 이유는 가상 메모리는 물리 메모리 주소 + 디스크의 일정량이기 때문이다.
C드라이브를 보면 pagefile.sys 라는 파일을 본 적이 있을 것이다.(물론 해당 파일은 설정에 따라 위치가 틀리다.) 해당 파일은 디스크 영역을 메모리와 같이 사용하기 위해 윈도우에서 생성한 파일이며 가상 메모리의 크기는 실제 메모리 + 해당 파일의 크기임을 알 수 있다.
(권장 값은 실제 메모리 * 1.5)
물리적 메모리와 가상 메모리의 값은 dxdiag에서 확인할 수 있으며 설정에 들어가서 확인할 수 있다.
http://www.youtube.com/watch?v=L2igH6O0ARM
(위 사이트는 메모리 설정 관련 사이트 임)
[그림 2] dxdiag에서 메모리 확인
그림 2에서 메모리는 실제 물리적 메모리이며 페이지 파일은 pagefiles.sys에 할당된 디스크의 메모리 용량을 의미한다.
프로그래머의 입장에서는 가상 메모리의 주소를 사용함으로써 실제 메모리와 페이지 파일에 어떤 페이지를 올려놓을지에 대해서 고려하지 않고 주소로만 처리함으로써 복잡한 알고리즘에서 벗어날 수 있으며 해당 페이지를 실제 메모리에 올리는 메커니즘은 운영체제에서 수행함으로써 물리 메모리 충동과 같은 이슈사항을 최소한으로 줄일 수 있는 것이다.
이런 가상 주소를 사용하기 위한 방법으로 페이징과 세그먼트라는 개념이 존재한다.
해당 방법에 대해 알아보도록 하겠다.
2. 페이징 기법
페이징 기법을 설명하기 전에 페이지가 무엇인지 먼저 알아야할것이다.
우리가 실제 메모리를 사용하는 경우 일정 용량을 메모리로 사용하게 된다.
예를 들어 실제 메모리가 512KB의 시스템에서 1MB의 메모리를 필요로 하는 프로그램을 사용한다고 가정하자.
이런 경우 0~511KB의 부분만 메모리에 올려놓고 나머지 부분은 디스크에 놓은 후 512KB 이후의 메모리를 액세스 할때는 512KB이후의 메모리를 메모리에 올려야 할것이다.
간단한 상황이지만 어느쪽의 메모리가 필요한 것인가 또는 어느쪽의 메모리가 반복적으로 사용되는 경우를 생각하면 디스크와 메모리 간에 데이터 교환이 빈번히 일어날 것이며 이것은 서버에 큰 부하를 줄 것이라는 것을 쉽게 생각할 수 있다.
항상 요청하는 메모리는 예측할 수 없으므로 요구 메모리를 페이지(Page)라는 단위로 나누어 요청한 데이터 내용에 대해 Page 단위로 메모리에 적재하여 불연속적인 메모리 요청에 대해 처리할 수 있도록 하는 것이 페이징 기법이다.
이런 페이징 기법에서 가장 중요한 것은 하나의 페이지의 크기이다.
페이지의 크기가 너무 큰 경우 디스크와 메모리간의 스위칭(페이지 교체 기법)이 잦을 것이며 페이지의 크기가 너무 작은 경우에는 단편화가 일어날 수 있다. 여기서 페이지 교체 기법 과 단편화에 대해서는 뒤에서 알아보도록 하겠다.
그럼 실제 메모리와 가상 메모리의 블록에 대해 알아보도록 하겠다.
Frame(프레임) : 실제 Physical Memory를 일정한 크기로 나눈 블록
Page(페이지) : 가상 Memory를 일정한 크기로 나눈 블록
[그림 3] page와 frame 의 관계
하나의 페이지가 프레임을 할당받으면 물리적 메모리에 페이지가 적재되며 그외의 페이지는 디스크에 저장되어지게 된다.
이런 페이지와 프레임간의 연관관계를 가지고 있는 테이블이 존재하는데 이것을 가르켜 페이지 테이블이라고 한다.
하나의 프로세스는 하나의 페이지 테이블(Page Table)을 가지고 있다.
[그림 4] Page Table, TLB(출처 : 위키백과)
여기서 한가지 이슈는 매번 메모리를 참조해야하는 경우 페이지 테이블에서 모든 내용을 검색하여 해당 메모리 내용이 물리 메모리에 적재되어 있는지 확인해야하는 경우 부하가 상당하다는 것이다.
그래서 Intel Microprocessor의 경우 TLB(Translation Lookaside Buffer)라는 버퍼를 두고 이곳에 가상 메모리 위치와 실제 매핑되어진 메모리의 위치정보를 사용 빈도에 따라 일정 개수 유지함으로써 자주 사용되는 페이지에 대해서는 해당 TLB에서 빠르게 검색할 수 있는 일종의 Buffer를 두고 있다.
3. 세그먼트 기법
페이지는 용도와 상관없이 메모리에 적재되는 모든 요소를 동일한 용량으로 분할하여 적용한다.
반면 세그먼트는 프로그램과 관련된 데이터를 용도에 따라 나누어 관리를 하게 되며 크기는 용도에 따라 다르다.
간단하게 생각하면 메모리에 적재되는 데이터는 여러 종류로 나뉘어져 있다.
우리가 사용하는 프로그램의 코드, 데이터, 아이콘이나 메뉴가 들어있는 리소스, 디버깅 정보등과 같이 메모리에 적재되는 부분을 용도에 따라 구분하여 나누는 것을 의미한다.
각 세그먼트들의 관리는 물리적 메모리의 위치로 하지 않고 각 세그먼트에 따라 상대적으로 offset 0에서 시작되게 되어 있다.
즉, 코드부도 0에서 메모리가 시작되어지며 데이터 부분도 0에서 메모리가 시작되어지게 되어있는 것이다.
각 세그먼트의 논리적 주소 공간과 실제 메모리의 물리적 기억장치의 위치는 세그먼트 테이블에 의해 매핑되어 관리하고 있다.

그래서 Intel Microprocessor의 경우 TLB(Translation Lookaside Buffer)라는 버퍼를 두고 이곳에 가상 메모리 위치와 실제 매핑되어진 메모리의 위치정보를 사용 빈도에 따라 일정 개수 유지함으로써 자주 사용되는 페이지에 대해서는 해당 TLB에서 빠르게 검색할 수 있는 일종의 Buffer를 두고 있다.
3. 세그먼트 기법
페이지는 용도와 상관없이 메모리에 적재되는 모든 요소를 동일한 용량으로 분할하여 적용한다.
반면 세그먼트는 프로그램과 관련된 데이터를 용도에 따라 나누어 관리를 하게 되며 크기는 용도에 따라 다르다.
간단하게 생각하면 메모리에 적재되는 데이터는 여러 종류로 나뉘어져 있다.
우리가 사용하는 프로그램의 코드, 데이터, 아이콘이나 메뉴가 들어있는 리소스, 디버깅 정보등과 같이 메모리에 적재되는 부분을 용도에 따라 구분하여 나누는 것을 의미한다.
각 세그먼트들의 관리는 물리적 메모리의 위치로 하지 않고 각 세그먼트에 따라 상대적으로 offset 0에서 시작되게 되어 있다.
즉, 코드부도 0에서 메모리가 시작되어지며 데이터 부분도 0에서 메모리가 시작되어지게 되어있는 것이다.
각 세그먼트의 논리적 주소 공간과 실제 메모리의 물리적 기억장치의 위치는 세그먼트 테이블에 의해 매핑되어 관리하고 있다.
[그림 5] 세그먼트
시스템에서는 각 세그먼트의 offset 0의 위치에서 데이터를 참조하며 마이크로프로세서는 세그먼트 테이블을 참조하여 실제적인 물리적인 주소로 변환해주기 때문에 세그먼트 데이터를 다루기 쉽다.
세그먼트의 데이터는 비슷한 유형의 데이터이기 때문에 세그먼트 테이블에 속성 필드(읽기, 쓰기)를 집어넣어 권한을 통제할 수 있다.
비슷한 유형의 데이터를 그룹화 시키는 세그먼트는 많은 장점을 가지고 있지만 단편화(fragmentation)이라는 단점을 가지고 있다.
단편화란 Windows의 디스크 조각모음 프로그램을 통해 살펴보면 쉽게 알 수 있다.
디스크의 경우에도 파일이 적재되면 그 파일의 크기에 따라 공간을 할당하게 되는데 파일의 적재와 삭제가 반복되어 일어나면 작은 크기의 빈공간만이 남게되는 단편화가 일어난다.
(그림 6을 보면 빨간색의 조각난 디스크가 많아 새로운 디스크 할당이 되어질때 큰 파일을 올릴 수 없음을 확인할 수 있다.)
메모리에서도 마찬가지로 세그먼트는 일정 크기가 아니기 때문에 메모리를 올리고 내리는 작업을 반복하면 용량이 큰 빈 메모리 공간은 줄어들고 작은 메모리 공간만 남는 외부 단편화의 현상이 일어나게 된다.
세그먼트의 데이터는 비슷한 유형의 데이터이기 때문에 세그먼트 테이블에 속성 필드(읽기, 쓰기)를 집어넣어 권한을 통제할 수 있다.
비슷한 유형의 데이터를 그룹화 시키는 세그먼트는 많은 장점을 가지고 있지만 단편화(fragmentation)이라는 단점을 가지고 있다.
단편화란 Windows의 디스크 조각모음 프로그램을 통해 살펴보면 쉽게 알 수 있다.
디스크의 경우에도 파일이 적재되면 그 파일의 크기에 따라 공간을 할당하게 되는데 파일의 적재와 삭제가 반복되어 일어나면 작은 크기의 빈공간만이 남게되는 단편화가 일어난다.
(그림 6을 보면 빨간색의 조각난 디스크가 많아 새로운 디스크 할당이 되어질때 큰 파일을 올릴 수 없음을 확인할 수 있다.)
메모리에서도 마찬가지로 세그먼트는 일정 크기가 아니기 때문에 메모리를 올리고 내리는 작업을 반복하면 용량이 큰 빈 메모리 공간은 줄어들고 작은 메모리 공간만 남는 외부 단편화의 현상이 일어나게 된다.
이런 단편화를 없애기 위해서는 세그먼트의 크기를 작게 만드는 것인데 해당 개념은 페이징 기법과 동일하기 때문에 Intel 80x86 계열에서는 세그먼트와 페이징을 병합하여 사용한다.
이러한 세그먼트와 페이징을 병합하여 사용하는 방식은 다음장에서 알아볼 것이다.
이러한 세그먼트와 페이징을 병합하여 사용하는 방식은 다음장에서 알아볼 것이다.
윈도우의 메모리를 알아 보기 전 Intel 80x86 계열에서의 메모리 처리 기법에 대해 먼저 알아보기로 하자.
1. 가상 주소
운영 체제에서 제공하는 메모리 관리기법으로 실제 메모리와 운영체제의 도움으로 하드디스크까지 메모리의 보조적인 기억장치(Paging Space)를 포함하는 주소를 의미한다.
[그림1] 메모리의 가상 주소 및 실제 주소(출처 : 위키백과)
그림 2에서 메모리는 실제 물리적 메모리이며 페이지 파일은 pagefiles.sys에 할당된 디스크의 메모리 용량을 의미한다.
프로그래머의 입장에서는 가상 메모리의 주소를 사용함으로써 실제 메모리와 페이지 파일에 어떤 페이지를 올려놓을지에 대해서 고려하지 않고 주소로만 처리함으로써 복잡한 알고리즘에서 벗어날 수 있으며 해당 페이지를 실제 메모리에 올리는 메커니즘은 운영체제에서 수행함으로써 물리 메모리 충동과 같은 이슈사항을 최소한으로 줄일 수 있는 것이다.
이런 가상 주소를 사용하기 위한 방법으로 페이징과 세그먼트라는 개념이 존재한다.
해당 방법에 대해 알아보도록 하겠다.
2. 페이징 기법
페이징 기법을 설명하기 전에 페이지가 무엇인지 먼저 알아야할것이다.
우리가 실제 메모리를 사용하는 경우 일정 용량을 메모리로 사용하게 된다.
예를 들어 실제 메모리가 512KB의 시스템에서 1MB의 메모리를 필요로 하는 프로그램을 사용한다고 가정하자.
이런 경우 0~511KB의 부분만 메모리에 올려놓고 나머지 부분은 디스크에 놓은 후 512KB 이후의 메모리를 액세스 할때는 512KB이후의 메모리를 메모리에 올려야 할것이다.
간단한 상황이지만 어느쪽의 메모리가 필요한 것인가 또는 어느쪽의 메모리가 반복적으로 사용되는 경우를 생각하면 디스크와 메모리 간에 데이터 교환이 빈번히 일어날 것이며 이것은 서버에 큰 부하를 줄 것이라는 것을 쉽게 생각할 수 있다.
항상 요청하는 메모리는 예측할 수 없으므로 요구 메모리를 페이지(Page)라는 단위로 나누어 요청한 데이터 내용에 대해 Page 단위로 메모리에 적재하여 불연속적인 메모리 요청에 대해 처리할 수 있도록 하는 것이 페이징 기법이다.
이런 페이징 기법에서 가장 중요한 것은 하나의 페이지의 크기이다.
페이지의 크기가 너무 큰 경우 디스크와 메모리간의 스위칭(페이지 교체 기법)이 잦을 것이며 페이지의 크기가 너무 작은 경우에는 단편화가 일어날 수 있다. 여기서 페이지 교체 기법 과 단편화에 대해서는 뒤에서 알아보도록 하겠다.
그럼 실제 메모리와 가상 메모리의 블록에 대해 알아보도록 하겠다.
Frame(프레임) : 실제 Physical Memory를 일정한 크기로 나눈 블록
Page(페이지) : 가상 Memory를 일정한 크기로 나눈 블록
하나의 페이지가 프레임을 할당받으면 물리적 메모리에 페이지가 적재되며 그외의 페이지는 디스크에 저장되어지게 된다.
이런 페이지와 프레임간의 연관관계를 가지고 있는 테이블이 존재하는데 이것을 가르켜 페이지 테이블이라고 한다.
하나의 프로세스는 하나의 페이지 테이블(Page Table)을 가지고 있다.
[그림 4] Page Table, TLB(출처 : 위키백과)
[그림 6] 디스크 조각모음
1. 가상 주소
운영 체제에서 제공하는 메모리 관리기법으로 실제 메모리와 운영체제의 도움으로 하드디스크까지 메모리의 보조적인 기억장치(Paging Space)를 포함하는 주소를 의미한다.
그림 1에서 보는 바와 같이 가상 메모리 주소는 실제 메모리 주소와 메핑되어 있으며 page 단위로 나누어져 있다.
page는 다음에 알아보기로 하며 해당 page는 process가 사용하고 있는 page와 process가 사용하고 있지 않는 page로 나뉘어져 있다.
process에 속해 있다는 의미는 해당 page가 process가 구동되는 과정에 사용되어지는 메모리라는 것을 의미한다.
여기서 그림 1을 보면 가상 메모리 주소의 크기가 물리 메모리 주소보다 큰 것을 볼 수 있다.
그 이유는 가상 메모리는 물리 메모리 주소 + 디스크의 일정량이기 때문이다.
C드라이브를 보면 pagefile.sys 라는 파일을 본 적이 있을 것이다.(물론 해당 파일은 설정에 따라 위치가 틀리다.) 해당 파일은 디스크 영역을 메모리와 같이 사용하기 위해 윈도우에서 생성한 파일이며 가상 메모리의 크기는 실제 메모리 + 해당 파일의 크기임을 알 수 있다.
(권장 값은 실제 메모리 * 1.5)
물리적 메모리와 가상 메모리의 값은 dxdiag에서 확인할 수 있으며 설정에 들어가서 확인할 수 있다.
http://www.youtube.com/watch?v=L2igH6O0ARM
(위 사이트는 메모리 설정 관련 사이트 임)
page는 다음에 알아보기로 하며 해당 page는 process가 사용하고 있는 page와 process가 사용하고 있지 않는 page로 나뉘어져 있다.
process에 속해 있다는 의미는 해당 page가 process가 구동되는 과정에 사용되어지는 메모리라는 것을 의미한다.
여기서 그림 1을 보면 가상 메모리 주소의 크기가 물리 메모리 주소보다 큰 것을 볼 수 있다.
그 이유는 가상 메모리는 물리 메모리 주소 + 디스크의 일정량이기 때문이다.
C드라이브를 보면 pagefile.sys 라는 파일을 본 적이 있을 것이다.(물론 해당 파일은 설정에 따라 위치가 틀리다.) 해당 파일은 디스크 영역을 메모리와 같이 사용하기 위해 윈도우에서 생성한 파일이며 가상 메모리의 크기는 실제 메모리 + 해당 파일의 크기임을 알 수 있다.
(권장 값은 실제 메모리 * 1.5)
물리적 메모리와 가상 메모리의 값은 dxdiag에서 확인할 수 있으며 설정에 들어가서 확인할 수 있다.
http://www.youtube.com/watch?v=L2igH6O0ARM
(위 사이트는 메모리 설정 관련 사이트 임)
[그림 2] dxdiag에서 메모리 확인
그림 2에서 메모리는 실제 물리적 메모리이며 페이지 파일은 pagefiles.sys에 할당된 디스크의 메모리 용량을 의미한다.
프로그래머의 입장에서는 가상 메모리의 주소를 사용함으로써 실제 메모리와 페이지 파일에 어떤 페이지를 올려놓을지에 대해서 고려하지 않고 주소로만 처리함으로써 복잡한 알고리즘에서 벗어날 수 있으며 해당 페이지를 실제 메모리에 올리는 메커니즘은 운영체제에서 수행함으로써 물리 메모리 충동과 같은 이슈사항을 최소한으로 줄일 수 있는 것이다.
이런 가상 주소를 사용하기 위한 방법으로 페이징과 세그먼트라는 개념이 존재한다.
해당 방법에 대해 알아보도록 하겠다.
2. 페이징 기법
페이징 기법을 설명하기 전에 페이지가 무엇인지 먼저 알아야할것이다.
우리가 실제 메모리를 사용하는 경우 일정 용량을 메모리로 사용하게 된다.
예를 들어 실제 메모리가 512KB의 시스템에서 1MB의 메모리를 필요로 하는 프로그램을 사용한다고 가정하자.
이런 경우 0~511KB의 부분만 메모리에 올려놓고 나머지 부분은 디스크에 놓은 후 512KB 이후의 메모리를 액세스 할때는 512KB이후의 메모리를 메모리에 올려야 할것이다.
간단한 상황이지만 어느쪽의 메모리가 필요한 것인가 또는 어느쪽의 메모리가 반복적으로 사용되는 경우를 생각하면 디스크와 메모리 간에 데이터 교환이 빈번히 일어날 것이며 이것은 서버에 큰 부하를 줄 것이라는 것을 쉽게 생각할 수 있다.
항상 요청하는 메모리는 예측할 수 없으므로 요구 메모리를 페이지(Page)라는 단위로 나누어 요청한 데이터 내용에 대해 Page 단위로 메모리에 적재하여 불연속적인 메모리 요청에 대해 처리할 수 있도록 하는 것이 페이징 기법이다.
이런 페이징 기법에서 가장 중요한 것은 하나의 페이지의 크기이다.
페이지의 크기가 너무 큰 경우 디스크와 메모리간의 스위칭(페이지 교체 기법)이 잦을 것이며 페이지의 크기가 너무 작은 경우에는 단편화가 일어날 수 있다. 여기서 페이지 교체 기법 과 단편화에 대해서는 뒤에서 알아보도록 하겠다.
그럼 실제 메모리와 가상 메모리의 블록에 대해 알아보도록 하겠다.
Frame(프레임) : 실제 Physical Memory를 일정한 크기로 나눈 블록
Page(페이지) : 가상 Memory를 일정한 크기로 나눈 블록
[그림 3] page와 frame 의 관계
하나의 페이지가 프레임을 할당받으면 물리적 메모리에 페이지가 적재되며 그외의 페이지는 디스크에 저장되어지게 된다.
이런 페이지와 프레임간의 연관관계를 가지고 있는 테이블이 존재하는데 이것을 가르켜 페이지 테이블이라고 한다.
하나의 프로세스는 하나의 페이지 테이블(Page Table)을 가지고 있다.
[그림 4] Page Table, TLB(출처 : 위키백과)
여기서 한가지 이슈는 매번 메모리를 참조해야하는 경우 페이지 테이블에서 모든 내용을 검색하여 해당 메모리 내용이 물리 메모리에 적재되어 있는지 확인해야하는 경우 부하가 상당하다는 것이다.
그래서 Intel Microprocessor의 경우 TLB(Translation Lookaside Buffer)라는 버퍼를 두고 이곳에 가상 메모리 위치와 실제 매핑되어진 메모리의 위치정보를 사용 빈도에 따라 일정 개수 유지함으로써 자주 사용되는 페이지에 대해서는 해당 TLB에서 빠르게 검색할 수 있는 일종의 Buffer를 두고 있다.
3. 세그먼트 기법
페이지는 용도와 상관없이 메모리에 적재되는 모든 요소를 동일한 용량으로 분할하여 적용한다.
반면 세그먼트는 프로그램과 관련된 데이터를 용도에 따라 나누어 관리를 하게 되며 크기는 용도에 따라 다르다.
간단하게 생각하면 메모리에 적재되는 데이터는 여러 종류로 나뉘어져 있다.
우리가 사용하는 프로그램의 코드, 데이터, 아이콘이나 메뉴가 들어있는 리소스, 디버깅 정보등과 같이 메모리에 적재되는 부분을 용도에 따라 구분하여 나누는 것을 의미한다.
각 세그먼트들의 관리는 물리적 메모리의 위치로 하지 않고 각 세그먼트에 따라 상대적으로 offset 0에서 시작되게 되어 있다.
즉, 코드부도 0에서 메모리가 시작되어지며 데이터 부분도 0에서 메모리가 시작되어지게 되어있는 것이다.
각 세그먼트의 논리적 주소 공간과 실제 메모리의 물리적 기억장치의 위치는 세그먼트 테이블에 의해 매핑되어 관리하고 있다.
그래서 Intel Microprocessor의 경우 TLB(Translation Lookaside Buffer)라는 버퍼를 두고 이곳에 가상 메모리 위치와 실제 매핑되어진 메모리의 위치정보를 사용 빈도에 따라 일정 개수 유지함으로써 자주 사용되는 페이지에 대해서는 해당 TLB에서 빠르게 검색할 수 있는 일종의 Buffer를 두고 있다.
3. 세그먼트 기법
페이지는 용도와 상관없이 메모리에 적재되는 모든 요소를 동일한 용량으로 분할하여 적용한다.
반면 세그먼트는 프로그램과 관련된 데이터를 용도에 따라 나누어 관리를 하게 되며 크기는 용도에 따라 다르다.
간단하게 생각하면 메모리에 적재되는 데이터는 여러 종류로 나뉘어져 있다.
우리가 사용하는 프로그램의 코드, 데이터, 아이콘이나 메뉴가 들어있는 리소스, 디버깅 정보등과 같이 메모리에 적재되는 부분을 용도에 따라 구분하여 나누는 것을 의미한다.
각 세그먼트들의 관리는 물리적 메모리의 위치로 하지 않고 각 세그먼트에 따라 상대적으로 offset 0에서 시작되게 되어 있다.
즉, 코드부도 0에서 메모리가 시작되어지며 데이터 부분도 0에서 메모리가 시작되어지게 되어있는 것이다.
각 세그먼트의 논리적 주소 공간과 실제 메모리의 물리적 기억장치의 위치는 세그먼트 테이블에 의해 매핑되어 관리하고 있다.
[그림 5] 세그먼트
시스템에서는 각 세그먼트의 offset 0의 위치에서 데이터를 참조하며 마이크로프로세서는 세그먼트 테이블을 참조하여 실제적인 물리적인 주소로 변환해주기 때문에 세그먼트 데이터를 다루기 쉽다.
세그먼트의 데이터는 비슷한 유형의 데이터이기 때문에 세그먼트 테이블에 속성 필드(읽기, 쓰기)를 집어넣어 권한을 통제할 수 있다.
비슷한 유형의 데이터를 그룹화 시키는 세그먼트는 많은 장점을 가지고 있지만 단편화(fragmentation)이라는 단점을 가지고 있다.
단편화란 Windows의 디스크 조각모음 프로그램을 통해 살펴보면 쉽게 알 수 있다.
디스크의 경우에도 파일이 적재되면 그 파일의 크기에 따라 공간을 할당하게 되는데 파일의 적재와 삭제가 반복되어 일어나면 작은 크기의 빈공간만이 남게되는 단편화가 일어난다.
(그림 6을 보면 빨간색의 조각난 디스크가 많아 새로운 디스크 할당이 되어질때 큰 파일을 올릴 수 없음을 확인할 수 있다.)
메모리에서도 마찬가지로 세그먼트는 일정 크기가 아니기 때문에 메모리를 올리고 내리는 작업을 반복하면 용량이 큰 빈 메모리 공간은 줄어들고 작은 메모리 공간만 남는 외부 단편화의 현상이 일어나게 된다.
세그먼트의 데이터는 비슷한 유형의 데이터이기 때문에 세그먼트 테이블에 속성 필드(읽기, 쓰기)를 집어넣어 권한을 통제할 수 있다.
비슷한 유형의 데이터를 그룹화 시키는 세그먼트는 많은 장점을 가지고 있지만 단편화(fragmentation)이라는 단점을 가지고 있다.
단편화란 Windows의 디스크 조각모음 프로그램을 통해 살펴보면 쉽게 알 수 있다.
디스크의 경우에도 파일이 적재되면 그 파일의 크기에 따라 공간을 할당하게 되는데 파일의 적재와 삭제가 반복되어 일어나면 작은 크기의 빈공간만이 남게되는 단편화가 일어난다.
(그림 6을 보면 빨간색의 조각난 디스크가 많아 새로운 디스크 할당이 되어질때 큰 파일을 올릴 수 없음을 확인할 수 있다.)
메모리에서도 마찬가지로 세그먼트는 일정 크기가 아니기 때문에 메모리를 올리고 내리는 작업을 반복하면 용량이 큰 빈 메모리 공간은 줄어들고 작은 메모리 공간만 남는 외부 단편화의 현상이 일어나게 된다.
이런 단편화를 없애기 위해서는 세그먼트의 크기를 작게 만드는 것인데 해당 개념은 페이징 기법과 동일하기 때문에 Intel 80x86 계열에서는 세그먼트와 페이징을 병합하여 사용한다.
이러한 세그먼트와 페이징을 병합하여 사용하는 방식은 다음장에서 알아볼 것이다.
이러한 세그먼트와 페이징을 병합하여 사용하는 방식은 다음장에서 알아볼 것이다.