Cluster Virtual Adapter Windows Server 2008부터 Failover Cluster Network이 변경됨 2008 이전 3343 포트를 이용한 UDP Broadcast를 사용하고 모든 노드가 같은 Subnet에 있어야함 2008 이후 3343 포트를 이용한 Unicast 가능 Cluster Join 프로세스가 진행되기 전 TCP Communication이 사용되어짐 DHCP를 지원함 다른 Subnet에 Node가 위치할 수 있음 Cluster Virtual Adapter인 netft.sys가 가장 적절한 Network를 통해 통신 가능 IPv6 지원 Netft 드라이버는 터널링을 사용하여 가장 적절한 네트워크를 통해 패킷 전달 Microsoft Failover Cluster..
Failover Cluster Virtual Network Adapter 1. Node Health 모니터링 - Node 들 사이에서 가능하지 않은 노드들을 확인한다. - Ping이 아닌 안정적이고 보안에 강한 Request-Reply를 사용하는 Unicast를 사용한다. - 서버들 중에 반응하지 않는 서버가 있는 경우 Recovery Action을 수행함 2. Failover Cluster Virtual ADapter(NetFT) - NetFT는 Cluster에서 노드들 사이에서 모든 가능한 인터페이스를 사용하여 TCP연결을 Fault-Tolerant하는 Adapter이다. - Cluster들은 Cluster간 통신하기 위해 여러 개의 Cluster가능한 Adapter를 사용하는 구조이다. - Clus..
Cluster Log 분석 시 State Code 와 Status Code의 의미 1. Status Code net helpmsg [error_number] error 번호가 Cluster Log에 있는 경우에 net helpmsg를 사용하여 해당 Code의 내용을 확인할 수 있습니다. 예를들어 다음 내용의 경우를 살펴보겠습니다. 388.4e8::1999/06/09-20:20:57.281 [NM] Received advice that node 2 has failed with error 5. 5의 경우 cmd창에서 확인 결과 다음과 같습니다. 권한 이슈로 확인되어 지며 권한을 확인할 필요가 있습니다. 2. State Code Cluster Service는 group, resource, node state,..
Cluster Cluster 운영 시 고객이 가장 많이 하는 질문은 다음과 같습니다. “왜 Resource가 다른 node로 Failover된 거죠” 특히 Windows 2003이나 이전 버전의 경우 시간 소모가 많습니다. 그런 경우 가장 많이 처리하는 방법이 여기에 있습니다. Cluster의 MPS Report를 수집합니다. 이 방법은 CSS팀으로 데이터를 보내 일차 분석하는 경우 자주 쓰입니다. 모든 Node에서 Event Log를 확인합니다. 일반적으로 에러가 발생할 때(일반적으로 Event ID 1069) 부근을 바탕으로 System Event Log를 확인합니다. 그 시간과 비교하여 Application Event Log도 같이 확인합니다.(여기서 핵심은 처음에 발생한 오류가 대부분 그 주 원인..
Windows 2008 R2에 클러스터를 설치하기 위해 필요사항입니다. 1. Hardware, Software - 동일한 하드웨어 버전(32bit, 64bit, Itanium)에 설치 - 동일한 OS Version - 동일한 Service Pack과 Windows Patch 2. Network - 동일한 네트워크 어댑터를 사용할 경우 동일한 통신설정(속도, 이중모드, 흐름 제어 및 미디어 유형)을 사용 - 스위치 간의 설정을 비교하여 설정에 충돌이 없는지 확인 - 클러스터 서버에서 이름 확인을 위해 DNS가 필요합니다. - 같은 Domain에 모든 서버가 있어야 합니다. 추천하는 구성은 Member 서버 입니다. 3. Account -클러스터를 처음 만들거나 클러스터에 서버를 추가할 때 해당 클러스터의 ..
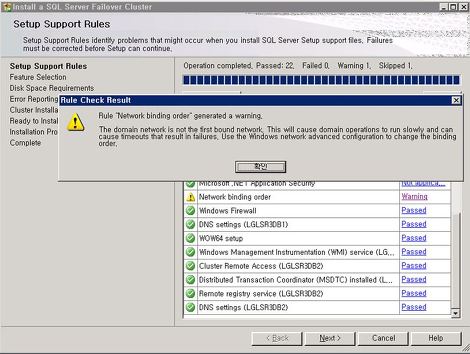
오늘은 Cluster 설치 시 Binding 이슈 발생에 대한 내용입니다. clustering 설치 시 Network Binding 관련하여 위와 같은 오류가 발생할 수 있습니다. 해당 오류는 네트워크 환경에서 Binding 순서를 정상적으로 정해놓았어도 숨김이나 Disable 네트워크가 Binding 순서에 영향을 미치기 때문에 발생합니다. 해결책은 다음과 같습니다. 1) set devmgt_Show_nonPersistent_devices=1 2) 네트워크 어댑터 목록을 확인하여 네트워크 설정에 표시되는 어뎁터 목록과 같은지 확인합니다. 3) 설치 전 비활성화된 어댑터를 제거합니다. 4) 설치 후 어댑터를 재설치 한 후 Disable 시킵니다. 참고 사이트 : http://technet.microsof..
오늘은 Windows 2003 Quorum 오류 해결 중 물리 Disk Fault에 대해 알아보도록 하겠습니다. 논리적으로 깨진 경우에 대해서는 다음에 설명하도록 하겠습니다. 물리 Disk가 Fault난 경우에는 해당 Disk를 교체 해야합니다. 하지만 Quorum 정족수가 부족한 경우에는 Cluster Service 자체가 실행되지 않기 때문에 교체 후에도 Cluster Service가 올라오지 않습니다. Quorum없이 강제로 실행하는 명령어를 수행하여 우선 Quorum 없이 Service를 기동시킵니다. net start clussvc /Fixquorum 해당 명령어를 수행하면 쿼럼 디스크 없이도 Service가 올라옵니다. 우선 서비스가 올라온 경우 Master Node를 제외한 Node는 Nod..
Windows 2003 기준의 쿼럼에 대해 설명하도록 하겠습니다. 1. 쿼럼 디스크 구성 방법 (1) 로컬 쿼럼 - 테스트용으로 사용하며 노드의 로컬 디스크에 쿼럼 정보를 저장하는 방식이다. - 다른 노드의 쿼럼과 동기화를 할 수 없기 때문에 일관성을 유지할 수 없다. - 단일 노드 구성에 사용하는 방법이다. (2) Node Majority(주노드) - 각 노드의 로컬 디스크에 쿼럼 정보를 저장하는 방식이다. - 다른 노드와 동기화가 되는 점이 로컬 쿼럼과 다른점이다. - 클러스터 서비스가 유지 되기 위해서는 과반수의 노드가 살아 있어야한다. 노드 갯수 주 노드 집합 허용 가능 오류 노드 수 1 1 0 2 2 0 3 2 1 4 3 1 5 3 2 6 4 2 7 4 3 8 5 3 (3) 표준 쿼럼 - 200..